
We are witnessing an unprecedented shift in the digital universe. Search is no longer just a list of blue links on Google. People are using ChatGPT, Google Gemini, Perplexity, and other AI-generated search engines to create instant conversational answers. Search engines aren’t just indexing your web pages; they are interpreting, summarizing, and synthesizing information from them through large language models (LLMs).
In this AI-driven ecosystem, websites are no longer passive content repositories. They are data sources for machine learning models.
The llms.txt file is a structured document that helps AI systems accurately understand your website. It outlines your site architecture, key page URLs, and simplified content—formatted in clean Markdown—so AI can interpret and surface your information more effectively.
Just like robots.txt guides search engine crawlers, llms.txt gives structured instructions to AI systems so they can correctly read, interpret, and use your website’s content. If you want your business to be cited, referenced, or surfaced in AI search results, you need to help these models understand your site.
That’s why understanding llms.txt is essential. It acts as a bridge that tells AI what your pages contain, what to prioritize, and what to exclude, ensuring your content appears accurately on the generative web.
As a leading AI SEO agency, we at BrandLoom believe this marks the beginning of a new era in search intelligence. Understanding what is llms.txt and how to implement it effectively can help brands maintain control over their data, improve AI SEO optimization, and secure their place in the next generation of online discovery.
What Is the LLMs.txt File?
The llms.txt file is a new protocol designed to help website owners communicate directly with Large Language Models (LLMs) such as ChatGPT, Gemini, Claude, and Perplexity. It serves as a guide that instructs these AI systems on how to access, utilize, or restrict your website’s data for AI training and content generation.
Think of llms.txt as the next evolution of robots.txt. While robots.txt was created to tell search engine bots what to crawl or ignore, llms.txt performs the same role for AI crawlers. It provides clear, structured instructions to AI models, helping maintain transparency about how web data is consumed for machine learning and response generation.
As the web shifts from being search-driven to AI-driven, this protocol has become essential. When users ask ChatGPT or Gemini for information, these tools do not simply display web pages. Instead, they generate human-like answers based on the data they have been trained on. This means that if your content is not managed correctly or represented, AI systems could interpret it incorrectly or worse, use it without consent.

The llms.txt file gives you a voice in that process. It lets you decide what portions of your website can be accessed by AI bots and what should remain private. For example, you might allow your blog or product descriptions to be used for contextual training but restrict AI from accessing gated reports, customer data, or premium content.
Here is a simple example of what an llms.txt file looks like:
# Sample llms.txt
User-Agent: GPTBot
Allow: /blog/
Disallow: /premium-content/
This short snippet communicates to AI crawlers that they are permitted to access the /blog/ directory but restricted from using any data within /premium-content/. The syntax mirrors the logic of robots.txt, making it easy for webmasters and SEOs to implement.
The Origin of LLMs.txt
The llms.txt file is an emerging protocol developed by community contributors and companies to communicate site-level preferences to AI crawlers. Adoption and interpretation vary by provider as of [Nov 2025].
As generative AI became mainstream, many publishers and content creators realized that their material was being used in model training without explicit consent. To address this, a group of open-source contributors, web standard organizations, and AI companies collaborated to establish llms.txt as a transparent, consent-based solution.
The initiative aims to build trust between AI developers and web publishers. It gives website owners the tools to define boundaries while still contributing to the broader ecosystem of knowledge. This collaborative effort is similar to the early days of robots.txt, which was introduced in 1994 to prevent aggressive web crawlers from overwhelming servers. Nearly three decades later, llms.txt carries that same spirit of digital governance—only now applied to AI intelligence rather than search indexing.
The file aligns with a growing movement toward responsible AI. By implementing llms.txt, websites can declare what type of interaction they allow, whether for training, contextual learning, or response generation. In doing so, they not only protect intellectual property but also encourage ethical data usage that respects both creators and consumers.
Why Does LLMs.txt Exist?
The rapid growth of large language models has created an unprecedented demand for high-quality data. Every time an AI model like ChatGPT or Claude learns from text on the internet, it essentially digests that content to understand patterns, tone, and meaning. This process fuels AI-driven knowledge discovery, but it also raises questions about consent, ownership, and data privacy.
Without clear boundaries, AI crawlers might pull information from sensitive areas, including private databases, paid resources, or personal user data. The llms.txt file exists to give publishers control back. It ensures that only the data you choose is accessible for AI learning or response generation.
In other words, llms.txt brings consent to the AI era. It creates a transparent communication channel between website owners and AI developers, ensuring that content usage aligns with ethical and legal standards. This approach supports a healthier digital ecosystem where AI and human creativity can coexist responsibly.
As the web transitions into an AI-first environment, the llms.txt file will become as fundamental to AI optimization as robots.txt is to SEO. It represents a crucial step toward maintaining balance, enabling innovation while protecting digital ownership.
Why Does LLMs.txt Matter for SEO & AI Visibility?
Over the past two decades, search engine optimization (SEO) has significantly influenced how brands present themselves online. Success depended on understanding algorithms, keywords, and backlinks to secure a place on Google’s first page. But the landscape has evolved. Today, AI engines like ChatGPT, Google Gemini, and Perplexity have become powerful content discovery platforms, changing how users find and consume information.
Market researchers such as Similarweb report a rapidly growing share of traffic from AI-driven platforms. For example, over 1.13 billion referral visits in June 2025, up 357% YoY. This means that people are no longer searching for links; they are asking for answers. And those answers are being generated by large language models (LLMs) trained on vast amounts of online data.
Here lies both the opportunity and the risk. Without proper controls, AI systems can use your content without acknowledgment or accuracy. A blog you published, a product description you crafted, or research data you created can easily be summarized, paraphrased, or even misrepresented in AI-generated responses. Worse, your brand might not even be mentioned as the source.
This is where llms.txt becomes critical. It acts as a digital boundary, telling AI crawlers what they can access, what they can use, and how they should interact with your site’s data.
When implemented correctly, llms.txt gives marketers and brand owners three major advantages:
- Control – Decide which sections of your website AI bots can crawl or use for training.
- Accuracy – Ensure that AI systems reference your most up-to-date and factual content.
- Transparency – Publicly declare how your data should be treated, aligning with ethical AI practices.

Essentially, llms.txt empowers you to shape your brand’s representation in the AI-driven discovery ecosystem.
Imagine your company runs a health information blog. Without llms.txt, an AI engine might pull outdated or incomplete data, generating misleading answers for users. With llms.txt, you can guide these AI crawlers to prioritize verified, accurate pages, reinforcing your authority and ensuring your insights are properly reflected in AI search results.
In an era where AI search visibility is replacing traditional search ranking, brands that manage their AI footprint will gain an edge. They will not just be seen, they will be understood.
The Transition from SEO to AEO
For decades, SEO was the foundation of online visibility. The goal was to rank higher on search engines like Google or Bing using keywords, backlinks, and optimized metadata. However, the rules of visibility are evolving. AI platforms no longer “rank” web pages; they interpret them. The focus has shifted from being visible to being comprehensible.
This shift gives rise to AEO (AI Engine Optimization), the practice of optimizing content so that AI systems can understand, trust, and accurately represent it. Unlike SEO, which primarily serves search algorithms, AEO ensures that AI language models can interpret the intent, tone, and authority of your content.
The llms.txt file is the first building block in this transformation. It allows AI crawlers to identify your site’s accessibility rules and understand which content is approved for learning or generation. When AI models like ChatGPT or Gemini process your data, these directives help them decide how to handle your content responsibly.
Here is how llms.txt plays a role in AEO:
- For ChatGPT (OpenAI): GPTBot uses llms.txt instructions to determine which sections of your site it can use for training or reference. If you disallow certain paths, that content will be excluded from AI summaries.
- For Google Gemini: As part of the broader Google ecosystem, GeminiBot may use llms.txt to enhance AI understanding while ensuring compliance with publisher preferences.
- For Perplexity AI: The platform relies on real-time data access; llms.txt helps define which URLs can be fetched for conversational search results.
By managing these AI interactions, you not only protect your content but also improve how your brand appears in AI-generated responses.
Let’s consider an example. Suppose your company is a sustainable fashion brand. A user asks an AI engine, “What are the top eco-friendly clothing brands in India?” If your content is correctly indexed, accessible, and approved for AI use through llms.txt, the AI model can confidently include your brand in its generated response. However, if your site blocks AI access entirely or lacks clear directives, your brand may never appear in these high-intent queries, resulting in lost opportunities for visibility and credibility.
This is why AI SEO optimization is becoming the next major pillar of digital strategy. Marketers who understand how to make their content discoverable to AI systems will lead in the new search landscape. The process starts with ensuring your site communicates clearly with AI crawlers through llms.txt, structured data, and semantic content organization.
Over time, AEO will influence how AI perceives expertise, authority, and trust (E-E-A-T), the same principles that define content quality in traditional SEO. Optimized llms.txt files will help establish these signals by showing AI engines that your brand values transparency, accuracy, and ethical data usage.
A New Era of Search Visibility
The rise of generative AI models for language has transformed how users interact with information. Instead of typing keywords into Google, people now hold conversations with AI. The responses they receive depend heavily on which sources the AI has learned from and how those sources are structured.
In this environment, llms.txt serves as your brand’s declaration of digital ethics and visibility. It ensures that your data contributes to AI models in a way that reflects your values and safeguards your reputation. It is more than a technical file; it is a communication tool between human creativity and machine intelligence.
Brands that adapt early will gain a distinct competitive advantage. By understanding and implementing llms.txt for SEO, marketers can position their content to thrive in the age of AI search optimization.
The question is no longer whether users will find you on Google; it is whether AI will understand and represent you accurately in the conversations shaping the future of the web.
How Does LLMs.txt Work?
The llms.txt file functions as a communication protocol between your website and AI crawlers such as GPTBot, ClaudeBot, GeminiBot, and PerplexityBot. It helps Large Language Models (LLMs) understand what content they are permitted to access, how that data can be used, and which areas should remain off-limits. In short, it gives website owners control over how AI systems consume their information.
Much like robots.txt, the llms.txt file operates using simple Allow and Disallow directives. But while robots.txt governs search engine crawlers, llms.txt regulates AI crawlers that collect or process data for training and content generation.
Here’s a step-by-step look at how it works:
1. Location: Placed at the Root of Your Domain
The llms.txt file must be stored in your website’s root directory — for example:
https://www.example.com/llms.txt
This is where AI crawlers first check for permissions before accessing or indexing your data. If llms.txt is missing, behavior varies: some crawlers may assume permissive access, while others may consult vendor policies or ignore content for training. Monitor logs to confirm.
2. Crawling: Read by AI Bots
When an AI system like ChatGPT or Claude begins scanning the web for data, its crawler bot first looks for the llms.txt file. This file contains instructions that tell the bot what it is allowed or disallowed to access.
For example:
User-Agent: GPTBot
Allow: /public-blog/
Disallow: /members-only/
In this snippet, GPTBot (OpenAI’s web crawler) is allowed to access your public blog posts but is restricted from using any data in the members-only section. This helps you manage AI data control at a granular level.
3. Instructions: Using Allow and Disallow Directives
Each AI crawler reads the User-Agent field to find its relevant permissions. You can specify multiple AI bots in one file, giving each different levels of access.
For example:
User-Agent: GPTBot
Allow: /articles/
User-Agent: ClaudeBot
Disallow: /research/
User-Agent: *
Disallow: /private/
In this case, GPTBot can read your articles, ClaudeBot is restricted from research pages, and all other bots (denoted by the asterisk *) are blocked from private directories.
These directives help ensure your data is used responsibly while still allowing AI systems to access relevant, non-sensitive information that benefits visibility.
4. Control: Transparency and Compliance
The most powerful feature of llms.txt is the control it gives to content creators and brands. Instead of leaving your content open to unregulated scraping, you can now define your own AI compliance policy.
This is particularly valuable for businesses that host proprietary research, paid data, or client-sensitive material. You can decide what to share with AI engines for discovery while keeping confidential areas protected. It also supports data ethics compliance, ensuring that AI models use your material within consent-based frameworks.
By regularly updating your llms.txt file, you can keep pace with new AI crawlers, evolving model architectures, and updates to data governance standards.
Supported AI Crawlers for LLMs.Txt
As the AI ecosystem grows, several major LLM providers have introduced their own web crawlers that respect llms.txt directives. Here are some of the key ones:
1. OpenAI – GPTBot
OpenAI’s GPTBot and other vendor crawlers may consult llms.txt directives. Vendors have signaled interest in site-level directives, but exact behavior and enforcement can differ by provider. Make sure to check vendor docs for the latest guidance. This ensures that content creators can choose whether their data contributes to OpenAI’s model improvement.
2. Anthropic – ClaudeBot
ClaudeBot powers Anthropic’s Claude AI systems. It operates similarly to GPTBot, reading llms.txt to determine which content it can use for contextual learning. This helps maintain data transparency and ethical compliance.
3. Google – GeminiBot
Google’s GeminiBot is expected to integrate both robots.txt and llms.txt protocols. It helps Google’s AI models interpret high-quality, publicly available data without infringing on protected content.
4. Perplexity – PerplexityBot
PerplexityBot supports real-time search and answer generation. It uses llms.txt to decide which URLs can be indexed and summarized in conversational responses.
As AI engines evolve, new crawlers will likely adopt this standard to ensure ethical AI training and fair use of web content.
Technical Mechanics Of LLMs.Txt
Under the hood, AI crawlers use a structured process to interpret llms.txt:
- File Discovery: The crawler sends an HTTP request to https://domain.com/llms.txt.
- HTTP Status Check: The bot looks for a 200 (OK) response. If it receives 404 (Not Found), the crawler assumes there are no restrictions.
- Caching Behavior: Crawlers often cache llms.txt for efficiency, checking back periodically for updates.
- Directive Parsing: The bot reads Allow and Disallow instructions line by line, applying them before accessing other site resources.
- Fallback Mechanisms: If llms.txt is missing or corrupted, most crawlers revert to default behavior (typically full access).
This simple yet powerful mechanism ensures transparency, accountability, and ethical data sharing between content creators and AI systems.
The AI Governance Consortium, along with major technology companies, is currently working to standardize how llms.txt directives are interpreted across different models. These standards will ensure that AI bots follow consistent and transparent rules worldwide, much like the unified adoption of robots.txt decades ago.
As generative AI continues to expand, llms.txt will become a cornerstone of AI data governancea necessary safeguard for businesses that want to participate in the AI-powered web while maintaining ownership and control of their intellectual property.
LLMs.txt vs Robots.txt: How Are They Different From Each Other?
Robots.txt controls crawling/indexing for search engines; llms.txt is intended to communicate preferences about AI usage and training. They are complementary, not interchangeable. While both are simple text files that guide digital crawlers, their objectives are distinct and complementary.
| Feature | robots.txt | llms.txt |
| Purpose | Controls what search engines can crawl and index | Controls how AI models use website data for learning or generating responses |
| Used By | Search engine bots like Googlebot or Bingbot | AI agents like GPTBot, ClaudeBot, GeminiBot, and PerplexityBot |
| Impact | Influences SEO visibility in search rankings | Influences AI visibility and representation across AI-driven platforms (AEO) |
| Example | User-Agent: Googlebot | User-Agent: GPTBot |
Why Do They Coexist Together?
The digital landscape is expanding beyond traditional search engines. While robots.txt determines what gets indexed in Google or Bing, llms.txt defines how your brand is represented in AI-powered summaries, chat responses, and generated insights.
These two files are not in competition; they complement each other. Think of robots.txt as managing visibility, and llms.txt as managing interpretation. Together, they provide a full spectrum of control over how your content is discovered, accessed, and reused.
For example, a blog post blocked by robots.txt won’t appear in search results, but if the same post isn’t restricted in llms.txt, it might still inform AI models like ChatGPT. Conversely, by fine-tuning llms.txt, brands can decide what content AI systems can reference, ensuring accurate representation and ethical usage.
In short, robots.txt shapes your SEO presence, while llms.txt safeguards your AI presence. Both are essential for digital governance in an era where AI-generated content influences user decisions as much as search results.
Common Misconceptions When It Comes to LLMs.Txt
One common misconception is that llms.txt replaces robots.txt. It does not. The two operate in different domains. Robots.txt handles web crawling and indexing its purpose is to control visibility within search engines. LLMs.txt, however, manages data rights and usage it governs consent for AI learning and response generation.
Another misconception is that llms.txt blocks all AI access by default. In reality, it’s a flexible tool. Website owners can selectively allow or disallow access to sections of their site. This ensures a balance between openness and protection empowering brands to share knowledge responsibly while safeguarding premium or sensitive data.
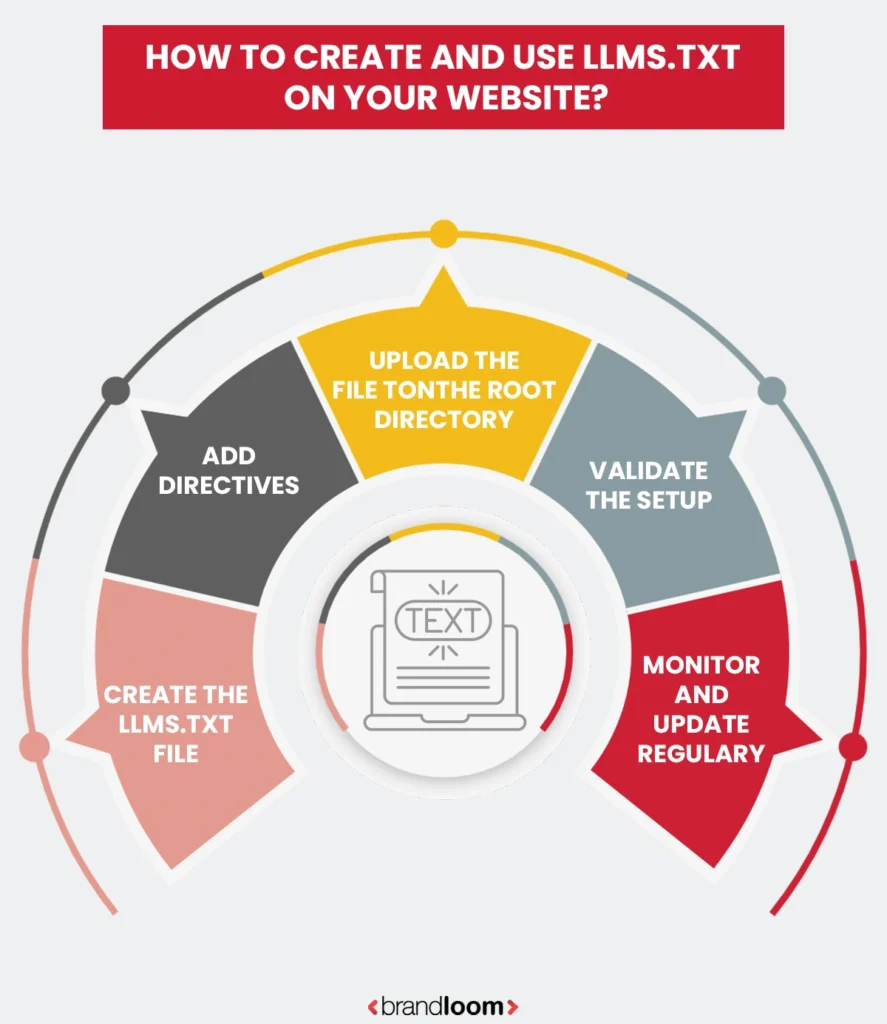
How to Create and Use LLMs.txt on Your Website
Setting up an llms.txt file is one of the most important steps in making your website AI-ready. Much like robots.txt, this small file gives you control over how AI models like ChatGPT, Gemini, Claude, and Perplexity access and use your site’s content. Whether you manage a small blog or a large enterprise website, implementing llms.txt ensures transparency, compliance, and improved AI visibility.
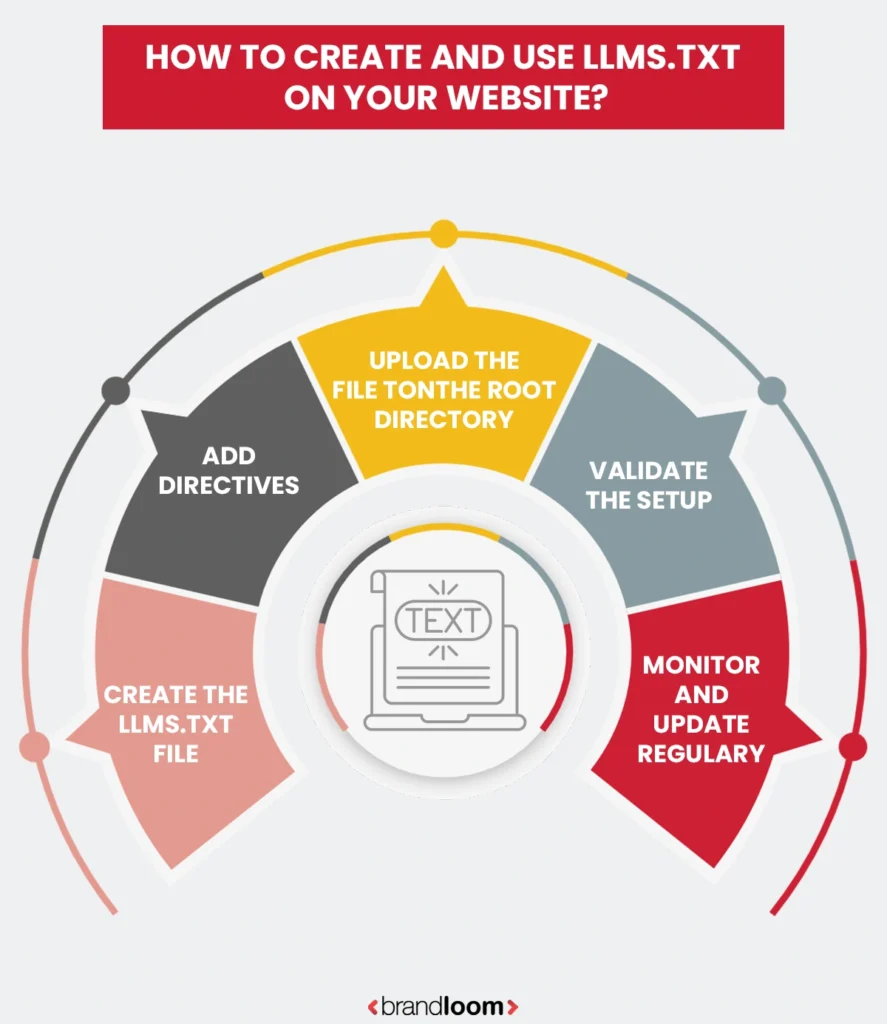
Step-by-Step Guide on How to Create and Use LLMs.txt
1. Create the llms.txt file
Start by opening any simple text editor such as Notepad or VS Code. Save a blank file as llms.txt. This file should follow standard text encoding (UTF-8) to ensure readability by AI crawlers.
2. Add Directives
Inside the file, define what parts of your website AI bots can access using Allow and Disallow directives. You can also specify which bots these rules apply to.
Example:
User-Agent: GPTBot
Allow: /blog/
Disallow: /premium-content/
In this case, OpenAI’s GPTBot can access the blog section but is restricted from premium content.
3. Upload the File to the Root Directory
Upload the llms.txt file to your domain’s root folder, ensuring it’s publicly accessible at:
https://www.example.com/llms.txt
This placement allows AI crawlers to find the file automatically, similar to how search engines locate robots.txt.
4. Validate the Setup
After uploading, test the file’s accessibility in your browser by visiting the URL directly. You can also use AI crawler testing tools or log analysis software to confirm whether AI bots are detecting the file correctly.
5. Monitor and Update Regularly
Once the llms.txt file is live, monitor your server logs for AI bot activity. Look for entries from GPTBot, ClaudeBot, GeminiBot, and others. Update your file periodically to reflect changes in site structure or privacy preferences.
Best Practices for LLMs.txt

1. Use Exact Paths
Be precise when defining URLs or directories. For instance, “/blog/” affects all blog pages, while “/blog/post-name/” targets only one page.
2. Avoid Overblocking
Disallowing too many sections may reduce your site’s AI visibility. Aim for a balance between data protection and discoverability.
3. Keep Syntax Clean and UTF-8 Encoded
Even minor syntax errors can make the file unreadable. Always use a plain text editor and ensure UTF-8 encoding.
4. Review Quarterly
AI agents evolve rapidly. Review your llms.txt directives every quarter to adapt to new crawlers, policy updates, or shifts in your site’s content strategy.
5. Align with Your Privacy Policy
Your llms.txt rules should reflect your company’s privacy and data ethics standards. If your policy restricts AI scraping of user data, make sure your file enforces it clearly.
Common Mistakes Associated With LLMs.txt

1. Mixing robots.txt Syntax
Although both files look similar, llms.txt uses slightly different directives. Avoid copying your robots.txt rules directly; instead, tailor them to AI crawlers.
2. Forgetting Updates After Site Migration
When you move your website to a new domain or hosting platform, update and re-upload your llms.txt file. Otherwise, AI crawlers might access outdated or incorrect instructions.
3. Overusing Disallow Directives
Completely disallowing all content can prevent AI systems from learning about your brand, leading to invisibility in AI-driven results and generative search summaries.
Advanced Tips For Using LLMs.txt

1. Create Custom Rules for Specific AI Bots
Different AI companies interpret content differently. For example, GPTBot may follow standard directives, while ClaudeBot might check for compliance-related signals. Use custom rules to manage them individually:
User-Agent: ClaudeBot
Disallow: /internal-data/
2. Combine LLMs.txt with AI Policy Pages
Transparency builds trust. Consider linking to an AI Policy or Data Use page that explains how you want AI systems to handle your data. This reinforces your brand’s ethical approach to AI.
3. Integrate Structured Data and Metadata
Adding schema markup and metadata helps AI crawlers understand your site context more accurately. Combined with llms.txt, structured data improves your content’s appearance in AI-generated responses and summaries.
4. Monitor Compliance Through Analytics
Use server analytics and AI monitoring tools to verify that crawlers are following your llms.txt rules. Detect and block unauthorized bots if necessary.
5. Test Across AI Models
Not all models read llms.txt the same way. Regularly test your configuration against popular AI agents, such as GPTBot, GeminiBot, and PerplexityBot, to ensure consistent performance.
In summary, setting up llms.txt gives your website a proactive stance in the AI-driven internet era. It strengthens transparency, protects your content rights, and ensures AI engines interpret your data accurately. When combined with structured metadata and ethical data-sharing practices, llms.txt becomes an essential layer in your broader AI SEO strategy helping your brand stay visible, relevant, and trustworthy as AI search evolves.
What’s Next for LLMs.txt and AEO
The evolution of llms.txt represents a major step in how websites communicate with artificial intelligence. Just as robots.txt became a universal standard for web indexing, llms.txt is poised to become the foundation of ethical AI data governance. In the coming years, this small text file will grow into a powerful mechanism shaping the intersection of transparency, data rights, and AI search visibility.
AI-driven discovery is no longer a distant future it’s already here. Platforms like ChatGPT, Gemini, and Perplexity are transforming how users find information. Instead of browsing search results, users now receive synthesized insights generated directly from web data. This new paradigm means websites must optimize not only for search engines but also for AI engines.
As AI adoption accelerates, llms.txt will likely evolve into a global protocol standard. It will serve as a compliance layer that allows AI models to learn from websites responsibly, with consent and attribution. Expect large AI providers such as OpenAI, Google, and Anthropic to roll out AI Search Consoles dashboards similar to Google Search Console, helping brands analyze how AI systems interpret and reference their content.
Future iterations of llms.txt may also integrate with structured data and metadata to improve AI ranking signals. By combining schema markup with llms.txt directives, websites could provide context about brand authority, freshness, and factual accuracy factors that AI engines use to assess reliability.
Governments, too, are beginning to recognize the importance of this emerging protocol. Policymakers are increasingly focused on AI transparency; future guidance or regulations may reference site-level disclosure mechanisms like llms.txt, but this is not certain. This evolution will push brands to formalize their AI content usage policies and adopt best practices in ethical AI engagement.
How Marketers Can Stay Ahead Of The Competition With LLMs.txt
To thrive in this AI-first landscape, marketers must look beyond traditional SEO and adopt AEO (AI Engine Optimization) as part of their broader digital strategy.
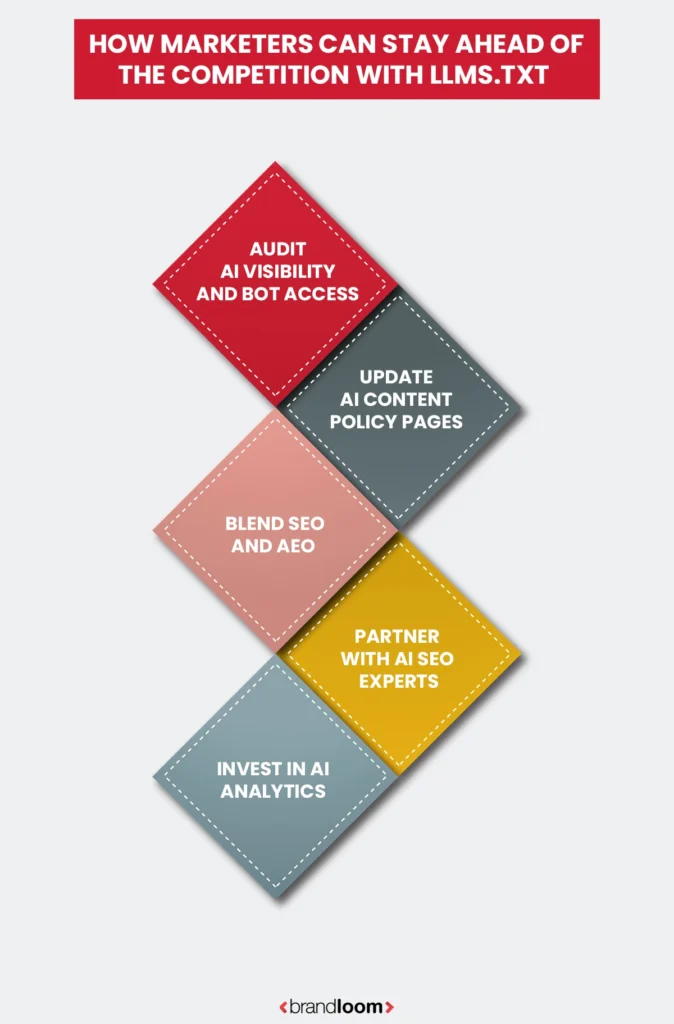
1. Audit AI Visibility and Bot Access
Just as you track search rankings, begin monitoring how AI platforms reference your brand. Regularly check access logs to see which AI bots are crawling your site and ensure your llms.txt settings align with your content strategy.
2. Update AI Content Policy Pages
Transparency will be a key ranking signal in AI search. Maintain a dedicated AI content policy page outlining how your brand permits data use. This not only builds user trust but also signals credibility to AI crawlers.
3. Partner with AI SEO Experts
Working with specialized agencies like BrandLoom, which understands both traditional SEO and emerging AEO frameworks, ensures your site remains competitive. BrandLoom helps brands align their llms.txt configurations, metadata, and structured data for maximum AI visibility.
4. Blend SEO and AEO
The most successful digital strategies will merge SEO (Search Engine Optimization) with AEO (AI Engine Optimization). While SEO focuses on keywords, backlinks, and rankings, AEO emphasizes data clarity, authority, and ethical accessibility for AI systems. Together, they create a future-proof visibility model across both search and generative AI ecosystems.
5. Invest in AI Analytics
As AI providers introduce visibility dashboards, leverage these tools to understand how your content performs in AI-generated summaries, snippets, and conversational search results. Use these insights to refine your messaging and optimize your site for generative discovery.
The future of llms.txt is more than a technical update; it’s a shift in digital ethics and content ownership. Brands that adopt it early will gain not only AI search visibility but also consumer trust, a critical advantage in a landscape defined by intelligent systems and data transparency.
By embracing llms.txt and aligning with AEO best practices today, you prepare your brand for tomorrow’s search reality where AI engines, not just algorithms, shape what audiences see, trust, and believe.
Conclusion
The rise of LLMs.txt marks a turning point in how brands interact with artificial intelligence. It is more than a technical file it is your bridge to AI visibility, data transparency, and ethical content control. By defining how AI engines like ChatGPT, Gemini, and Claude engage with your site, LLMs.txt ensures your brand is accurately represented in the new era of AI-driven discovery.
To recap, you now understand what LLMs.txt is, how it works, and why it matters. It allows website owners to guide AI crawlers responsibly, protect sensitive data, and enhance AI Engine Optimization (AEO) the next evolution of SEO. Implementing it correctly is your first step toward future-proofing your brand as AI search optimization becomes mainstream.
Acting early can position your business as a leader in AI visibility. As search transitions from engines to intelligent assistants, your website must communicate not just with humans, but also with algorithms that learn and generate insights.
At BrandLoom, we help forward-thinking brands adapt to this transformation. Our team of AI SEO experts combines deep expertise in SEO, AEO, and AI-driven strategy to make your website discoverable, compliant, and future-ready. Whether you’re building an LLMs.txt file or optimizing your data for generative search, BrandLoom ensures your digital presence stays ahead of evolving AI standards.
The future of online visibility belongs to brands that prepare today. Begin your LLMs.txt journey now and make sure your content helps train, not trail, the next generation of AI discovery.
Frequently Asked Questions
An LLMs.txt file is a web protocol that communicates with Large Language Models (LLMs) like ChatGPT, Gemini, Claude, and Perplexity. It guides AI crawlers on which parts of your website they can read or use for training and generative responses. Similar to robots.txt for search engines, it gives you control over AI usage of your content.
LLMs.txt contains simple directives such as Allow and Disallow, helping AI bots respect content boundaries while maintaining visibility in AI search results. As one of the top AI SEO companies in India, we at BrandLoom assist businesses in creating and optimizing LLMs.txt files.
The key difference between LLMs.txt and robots.txt lies in their audience and purpose. Robots.txt is designed for search engine crawlers like Googlebot or Bingbot and focuses on controlling which pages are indexed, impacting SEO visibility.
LLMs.txt, on the other hand, guides AI models such as GPTBot, ClaudeBot, and GeminiBot on how they can use your site’s content for training or generative outputs. While robots.txt affects traditional rankings, LLMs.txt impacts AI search visibility and the accuracy of AI-generated responses.
Both can coexist, providing comprehensive governance over your website data. As one of the leading AI SEO agencies in India, we at BrandLoom help brands implement both files correctly. We ensure that robots.txt maintains search engine presence, while LLMs.txt manages AI content discovery and compliance, creating a dual-layer strategy for maximum visibility and ethical AI engagement.
Website owners should create an LLMs.txt file to maintain control over how AI systems access and use their content. Without it, AI models may scrape, summarize, or train on your data without consent, potentially misrepresenting your brand.
LLMs.txt allows you to define permissions, specifying what AI bots can or cannot use. This ensures ethical content usage and strengthens your presence in AI-driven search. It also protects sensitive content, premium resources, and proprietary information from unintended AI use.
As one of the best AI SEO companies in India, we at BrandLoom guide businesses in creating LLMs.txt files that balance protection and visibility. Proper implementation positions your brand for AI Engine Optimization (AEO) success, ensuring your content contributes meaningfully to generative AI outputs while maintaining trust and transparency in AI content discovery.
Using an LLMs.txt file provides both AI and SEO benefits. It ensures your website data is accessed responsibly by AI models, helping prevent misuse of content while maintaining transparency. LLMs.txt guides large language models on which pages to include or ignore, improving accuracy in AI-generated answers and ensuring your brand is represented correctly.
From a marketing perspective, it enhances AI search visibility, allowing businesses to influence how their content appears in generative search platforms. Additionally, it aligns with ethical AI practices and upcoming data privacy standards.
As one of the top AI SEO companies in India, we at BrandLoom help brands integrate LLMs.txt into broader AI SEO optimization strategies. Combining LLMs.txt with structured data, metadata, and privacy policies allows brands to maintain control, strengthen credibility, and future-proof their digital presence for the growing AI content discovery ecosystem.
Implementing an LLMs.txt file is simple but requires accuracy. Begin by creating a plain text file named llms.txt. Add directives like Allow or Disallow to indicate which pages or directories AI bots can access. You can also target specific AI crawlers, such as GPTBot, ClaudeBot, or GeminiBot, for more granular control.
Upload the file to your domain root (e.g., www.example.com/llms.txt). Test accessibility using AI crawler simulation tools to ensure proper interpretation. Review the file periodically as AI crawlers evolve and your website content changes.
As one of the leading AI SEO agencies in India, we at BrandLoom assist brands in end-to-end implementation, ensuring the file supports LLM optimization for websites while balancing visibility, transparency, and compliance. Proper setup ensures your site is AI-ready, contributing to accurate and ethical AI-generated results.
Several major AI crawlers currently recognize LLMs.txt. These include GPTBot from OpenAI, ClaudeBot from Anthropic, GeminiBot from Google, and PerplexityBot. Each bot reads the file to determine which parts of your website they can access for AI training or response generation.
LLMs.txt allows website owners to control data usage while improving AI search visibility.
Compliance may vary among crawlers, but ethical providers generally follow the file’s directives. As one of the top AI SEO companies in India, we at BrandLoom help businesses identify which crawlers visit their site, optimize their LLMs.txt files, and monitor access logs.
Yes, LLMs.txt can instruct AI models like ChatGPT, Gemini, or Claude not to access or train on certain pages. Using Disallow directives for specific bots restricts AI from scraping sensitive or proprietary content. For example:
User-Agent: GPTBot
Disallow: /premium-content/
However, compliance depends on the AI provider’s adherence to standards. Ethical AI systems respect the directives, while others may not yet fully enforce them. LLMs.txt provides a proactive way to protect content while maintaining visibility for permitted sections.
As one of the leading AI SEO agencies in India, we at BrandLoom guide brands on balancing protection with AI search optimization, ensuring sensitive content remains private while allowing public content to be discoverable and correctly represented in AI-generated outputs.
An effective LLMs.txt file includes structured directives such as User-Agent, Allow, and Disallow. Specify AI crawlers individually, like GPTBot, ClaudeBot, and GeminiBot, to ensure clear instructions. You can also link to your AI content policy page for transparency. Syntax should be clean, UTF-8 encoded, and organized logically to avoid errors. Example:
User-Agent: GPTBot
Allow: /blog/
Disallow: /members-only/
This setup protects sensitive content while enabling discoverability. As one of the top AI SEO companies in India, we at BrandLoom help brands craft LLMs.txt files tailored to content strategy, compliance, and AI SEO optimization. A well-structured file improves AI content discovery, ensures proper brand representation, and positions your website for generative search relevance.
Currently, LLMs.txt is optional but highly recommended. No law requires it yet, but its adoption signals responsible AI content governance. Much like robots.txt in early SEO, it provides control over AI usage and ensures content is ethically accessed.
Brands that implement LLMs.txt proactively are better positioned for AI Engine Optimization (AEO), improving visibility in AI-driven search results.
Waiting may mean losing control or falling behind competitors. As one of the best AI SEO agencies in India, we at BrandLoom advise early adoption to protect content, ensure compliance, and maximize AI search visibility while maintaining brand trust in generative search environments.
LLMs.txt is set to shape the future of AI search and generative content. It introduces transparency, consent, and control over how AI models learn from websites. As AI-driven platforms become dominant, LLMs.txt ensures content is represented accurately, ethically, and consistently.
It will likely integrate with structured data, metadata, and AI governance frameworks, impacting both SEO and AEO. Early adoption positions brands for credibility, visibility, and authority in the AI ecosystem. As one of the top AI SEO companies in India, we at BrandLoom guide brands in creating and maintaining LLMs.txt files, combining technical setup with strategy.
This ensures your website contributes positively to AI training, remains discoverable in AI content discovery, and is prepared for the evolving landscape of generative search SEO.





Comments are closed.